
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- MYSQL
- 이진탐색
- String
- Hash
- two pointer
- binary search
- Brute Force
- Trie
- 스토어드 프로시저
- union find
- 그래프
- 다익스트라
- DP
- Dijkstra
- Two Points
- Stored Procedure
- SQL
- Today
- Total
codingfarm
2. 아스키코드와 유니코드 본문
Windows 프로그래밍에서 GUI 프로그래밍을 하건, 시스템 프로그래밍을 하건 유니코드에 대한 이해는 필수적이다.
1. Windows 에서의 유니코드(UNICODE)
문자셋(Character Sets)의 종류와 특성
대표적인 문자셋으로 아스키코드(ASCII CODE)와 유니코드(UNICODE)가 있다.
| 아스키코드(ASCII CODE) | 유니코드(UNI CODE) |
| $\bullet$ 미국에서 정의하는 표준이다. $\bullet$ 크기 : 1byte (영어 + 특수문자가 256개 이하) |
$\bullet$ 전세계 문자를 표현하기 위한 표준 $\bullet$ 크기 : 2byte |
문자셋(character set)
$\bullet$ 문자들의 집합, 문자의 표현방법에 대한 약속
$\bullet$ 종류에 따라 아래와 같은 세가지로 나뉜다.
1. SBCS(Single Byte Character Set)
$\bullet$ 1byte만을 사용하는 문자 표현 방식
$\bullet$ 아스키코드가 대표적인 SBCS
2. WBCS(Wide Byte Character Set)
$\bullet$ 2byte 만을 사용하는 문자 표현 방식
$\bullet$ 유니코드가 대표적은 WBCS
3. MBCS(Multi Byte Character Set)
$\bullet$ 1byte 혹은 2byte의 다양한 크기를 사용해서 문자를 표현한다.
$\bullet$ 한글과 같은 대부분의 문자를 2byte로 처리하되 영어를 표현하는등 경우에 따라 1byte 로도 처리한다.
$\bullet$ 효율적으로 메모리를 관리하되 프로그램 구현에 세심한 주의가 필요하다.
MBCS 기반의 프로그래밍
아래 예를 살펴보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include<stdio.h>
#include<string.h>
int main(void) {
char str[] = "ABC한글";
int size = sizeof(str);
int len = strlen(str);
printf("배열의 크기 : %d \n", size);
printf("문자열의 길이 : %d \n", len);
return 0;
}
|
cs |

우선 배열의 크기부터 살펴보자
어떻게 8 byte가 나왓을까?
ABC(3 byte) + 한글(4 byte) + NULL 문자(1 byte) = 8 byte
영문은 1byte로 한글은 2byte로 섞여서 처리됨을 알 수 있다.
이것은 현재 MBCS기반임을 알 수 있다.
이번에는 문자열의 길이를 살펴보자 strlen은 길이계산에서 NULL 문자를 포함하지 않음에 주의한다.
ABC(길이 3) + 한글(길이 4) = 8 byte
"ABC한글" 의 길이는 5이지만 "한글" 이라는 단어는 길이가 4로 인식되고 있다.
MBCS의 문제점
1) 유니코드 기반의 문자열의 길이를 2로 계산한다.(유니코드와 아스키코드 혼합 사용시 혼란이 발생 할 수 있다.)
2) 1byte 문자와 2byte 문자의 혼합사용으로 혼란이 있을 수도 있다.
MBCS의 또다른 문제점을 아래 예로 확인하자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include<stdio.h>
int main(void) {
char str[] = "한글입니다";
int i;
for (i = 0; i < 5; i++)
fputc(str[i], stdout);
fputs("\n", stdout);
for (i = 0; i < 10; i++)
fputc(str[i], stdout);
fputs("\n", stdout);
return 0;
}
|
cs |

문자열 길이가 5임에도 불구하고 7,8번째 줄에서 fputc를 5번 호출해도 "한글" 2개의 문자만이 출력됨을 볼 수 있다.
5개의 문자를 모두다 출력하려면 12,13번째 줄처럼 fputc를 10번 호출해야한다.
문자열의 길이를 통해서 데이터의 크기를 예측할 수 없다는 것이 MBCS의 단점이다.
WBCS 기반의 프로그래밍
WBCS 기반의 프로그래밍을 위해선 몇가지 신경쓸 요소들이 있다.
char를 대신하는 wchar_t
$\bullet$ char형 변수는 1byte 메모리 공간만 할동되지만, wchar_t형 변수는 2byte 메모리 공간이 할당된다.
$\bullet$ 유니코드를 기반으로 문자를 표현하는것이 가능하다.
$\bullet$ wchar_t는 아래와 같은 형태로 선언되어 있다.
|
1
|
typedef unsigned short wchar_t;
|
cs |
"ABC"를 대신하는 L"ABC"
기존의 "ABC"는 MBCS기반 문자열이므로 새로운 방법이 필요하다.
다음은 자료형 wchar_t를 이용한 문자열의 선언이다.
|
1
|
wchar_t str[] = L"ABC";
|
cs |
배열 str은 유니코드 문자열을 저장할 준비가 되어있으므로 우변 또한 MBCS 기반 문자열이어야 한다.
문자열 앞의 문자 L은 "이어서 등장하는 문자열을 유니코드기반(WBCS)으로 표현하라"는 의미를 지닌다.
따라서 L"ABC"의 경우 NULL 문자를 포함해서 총 8byte로 표현된다.
유니코드에서는 문자열의 끝을 이미하는 NULL 문자 까지도 2byte로 처리된다.
strlen을 대신하는 wcslen
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include<stdio.h>
#include<string.h>
int main(void) {
wchar_t str[] = L"ABC";
int size = sizeof(str);
int len = wcslen(str);
printf("배열의 크기 : %d \n", size);
printf("문자열 길이 : %d \n", len);
return 0;
}
|
cs |

unsigned short자료형이 2byte의 크기를 가지므로 2*4(L"ABC" + NULL문자) = 8byte의 크기를 가진다는 직관과 일치한다.
MBCS로 작성시에 문자열길이가 7로 나왔던 것과 비교해보자
차지하는 메모리 크기가 2byte라 하더라도 하나의 문자로 인식함을 보여준다.
SBCS에 대응하는 WBCS기반의 문자열 함수들은 아래와 같다.
| SBCS 함수 | WBCS 기반의 문자열 조작 함수 |
| strlen | size_t wcslen (const wchar_t* string); |
| strcpy | wchar_t* wcscpy (wchar_t* dest, const wchar_t* src); |
| strncpy | wchar_t* wcsncpy (wchar_t* dest, const wchar_t* src, size_t cnt); |
| strcat | wchar_t* wcscat (wchar_t* dest, const wchar_t* src); |
| strcat | wchar_t* wcsncat (wchar_t* dest, const wchar_t* src, size_t cnt); |
| strcmp | int wcscmp ( const wchar_t* s1, const wchar_t* s2); |
| strncmp | int wcsncmp ( const wchar_t* s1, const wchar_t* s2, size_t cnt); |
SBCS기반 함수는 MBCS에서도 사용 가능하다.
size_t는 아래와 같이 정의되어 있다
|
1
|
typedef unsigned int size_t;
|
cs |
완전한 유니코드 기반으로 : 첫 번째
| SBCS 함수 | WBCS 기반의 문자열 입$\cdot$출력 함수 |
| printf | int wprintf (const wchar_t* format [, argument]...); |
| scanf | int wscanf (const wchar_t* format [, argument]...); |
| fgets | wchar_t* fgetws (wchar_t* string, int n, FILE* stream); |
| fputs | int fputws (const wchar_t* string, FILE* stream); |
이제 코드를 새로 작성해보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include<stdio.h>
#include<string.h>
int main(void) {
wchar_t str[] = L"ABC";
int size = sizeof(str);
int len = wcslen(str);
wprintf(L"Array Size : %d \n", size);
wprintf(L"String Length : %d \n", len);
return 0;
}
|
cs |
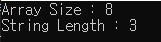
wprintf, fputws와 같은 함수들을 통해서 유니코드 기반으로 한글을 출력하고 싶다면 아래와같은 함수 호출 문장이 출력함수 호출 전에 들어가야 한다.
|
1
|
_wsetlocale (LC_ALL, L"korean");
|
cs |
프로그램이 실행되는 나라 및 지역에 대한 정보를 설정하는데 사용되는 함수이다.
완전한 유니코드 기반으로 : 두번째
main함수의 두번째 매개변수인 char* argv[] 는 SBCS기반이므로 이를 WBCS 기반으로 바꿔주기 위해 wchar_t* argv[] 로 바꾸어야 한다.
또한 main이라는 이름의 함수는 프로그램 실행시, 전달되는 문자열을 MBCS기반으로 구성하므로 wmain 으로 대체해야 한다.

|
1
2
3
4
5
6
7
8
9
10
|
#include<stdio.h>
int wmain(int argc, wchar_t* argv[]) {
for (int i = 1; i < argc; i++) {
fputws(argv[i], stdout);
fputws(L"\n", stdout);
}
return 0;
}
|
cs |
2. MBCS와 WBCS의 동시 지원
현존하는 시스템 모두가 완벽한 유니코드 기반을 지원하는 것이 아니기에 항상 WBCS만을 쓸수는 없다.
하나의 프로그램을 MBCS기반과 WBCS 기반으로 각각 나누는것도 번거롭다.
윈도우즈에서는 프로그램의 구현 한번만으로 MBCS와 WBCS 양쪽을 기반으로 컴파일 가능하게 하는 방법을 지원해준다.
$include<windows.h>
windows.h는 Windows 기반 프로그래밍을 하는데 있어서 기본적으로 항상 포함해야 하는 헤더파일이다.
기회가 된다면 정의되어 있는 파일이 무엇인지, 어떠한 경로를 통해서 windows.h에 포함되는지 확인해볼것
Windows에서 정의하고 있는 자료형
Windows 에서는 typedef 키워드를 통하여 몇몇 기본 자료형에 Windows 스타일의 새로운 이름을 정의하고 있다.
일부분만 알아보자
$$\begin{align*}
&typedef& &char& && &CHAR;&\\
&typedef& &wchar\_t& && &WCHAR;&\\\\
&\#define& &CONST& && &const;&\\\\
&typedef& &CHAR\;*& && &LPSTR;&\\
&typedef& &CONST& &CHAR\;*& &LPCSTR;&\\\\
&typedef& &WCHAR\;*& && &LPWSTR;&\\
&typedef& &CONST& &WCHAR\;*& &LPCWSTR;&
\end{align*}$$
const 대신 CONST를 쓴건 Windows 스타일의 자료형 이름이 대문자로 구성되는 흐름을 따라가기 위한것이다.
이제 모든 예제를 유니코드 기반으로 짜보겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#include<stdio.h>
#include<windows.h>
int wmain(int argc, wchar_t* argv[]) {
LPCSTR str1 = "SBCS Style String 1";
LPCWSTR str2 = L"WBCS Style String 1";
CHAR arr1[] = "SBCS Style String 2";
WCHAR arr2[] = L"WBCS Style String 2";
LPCSTR cStr1 = arr1;
LPCWSTR cStr2 = arr2;
printf("%s\n", str1);
printf("%s\n", arr1);
wprintf(L"%s\n", str2);
wprintf(L"%s\n", arr2);
return 0;
}
|
cs |
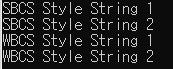
MBCS와 WBCS(유니코드)를 동시에 지원하기 위한 매크로
Windows 에서는 MBCS와 WBCS를 동시에 수용하는 형태의 프로그램을 구현을 위해서 매크로를 정의하고 있다.
다음은 Windows에 선언되어 있는 내용을 간략화 한것이다.
|
1
2
3
4
5
6
7
8
9
|
#ifdef UNICODE
typedef WCHAR TCHAR;
typedef LPWSTR LPTSTR;
typedef LPCWSTR LPCTSTR;
#else
typedef CHAR TCHAR;
typedef LPTSTR LPTSTR;
typedef LPCTSTR LPCTSTR;
#endif
|
cs |
위 매크로에 의해 어떠한 일들이 벌어지는지 예를 들어보겠다
아래와 같이 선언된 배열이 있다.
|
1
|
TCHAR arr[10];
|
cs |
만약에 UNICODE라는 매크로가 정의되어 있지 않다면, 전처리기에 의해서 다음과 같이 변경되어 MBCS 타입의 문자열 저장이 가능해진다.
|
1
|
CHAR arr[10];
|
cs |
반대로 UNICODE라는 매크로가 정의되어 있다면, 전처리기에 의해서 다음과 같이 변경되며, 이는 WBCS 기반의 문자열 저장을 가능하게 한다.
|
1
|
WCHAR arr[10];
|
cs |
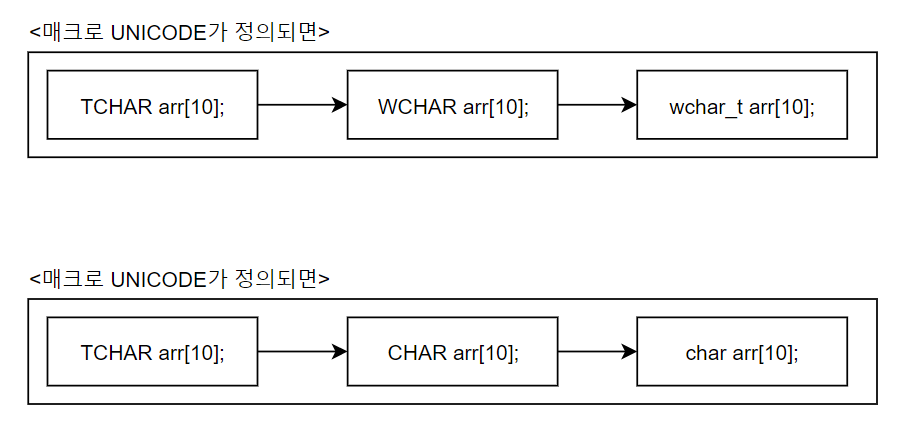
다음은 tchar.h에 선언된 내용 일부를 보기좋게 편집한것이다.
tchar.h는 windows.h에 포함되지 않는다.
|
1
2
3
4
5
6
7
8
|
#ifdef _UNICODE
#define __T(x) L ## x
#else
#define __T(x) x
#endif
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
|
cs |
예를 통해 살펴보자
|
1
|
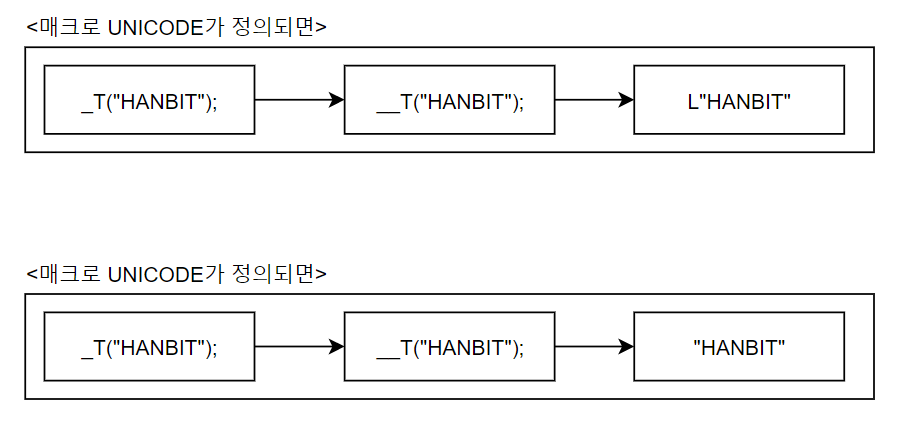
_T("HANBIT");
|
cs |
이 매크로는 아무 조건 없이 전처리기에 의해서 아래와 같이 변경될것이다.
|
1
|
__T("HANBIT");
|
cs |
위 문장은 _UNICODE 라는 매크로가 정의되어 있지 않다면, 아래와 같이 MBCS 타입의 문자열로 변경된다.
|
1
|
"HANBIT";
|
cs |
반대로 _UNICODE 라는 매크로가 정의되어 있다면, 아래와 같이 WBCS 기반의 문자열이 된다.
|
1
|
L"HANBIT";
|
cs |
정리하면 아래와 같다.
유니코드와 MBCS를 동시에 지원하는 프로그램의 예이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#define UNICODE
#define _UNICODE
#include<stdio.h>
#include<tchar.h>
#include<windows.h>
int wmain(void) {
TCHAR str[] = _T("1234567");
int size = sizeof(str);
printf("string length : %d \n", size);
return 0;
}
|
cs |

환경에 따라 결과가 다를것이다.
위 출력을 통해 내 컴파일러는 유니코드로 문자열을 읽음을 알 수 있다.
MBCS와 WBCS(유니코드)를 동시에 지원하기 위한 함수들
MBCS기반의 printf와 유니코드 기반의 wprintf를 자동으로 변환해주는 매크로를 살펴보자
|
1
2
3
4
5
|
#ifdef _UNICODE
#define _tprintf wprintf
#else
#define _tprintf printf
#endif
|
cs |
_UNICODE 정의에 따라 WBCS방식 혹은 MBCS방식으로 컴파일 된다.
tchar.h에 매크로 함수가 선언되어있다.

이제 예제를 작성해보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
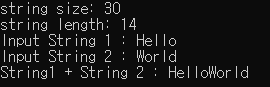
#include<stdio.h>
#include<tchar.h>
#include<windows.h>
int _tmain(int argc, TCHAR* argv[]) {
LPCTSTR str1 = _T("MBCS or WBCS 1");
TCHAR str2[] = _T("MBCS or WBCS 2");
TCHAR str3[100];
TCHAR str4[50];
LPCTSTR pStr = str1;
_tprintf(_T("string size: %d \n"), sizeof(str2));
_tprintf(_T("string length: %d \n"), _tcslen(str2));
_fputts(_T("Input String 1 : "), stdout);
_tscanf(_T("%s"), str3);
_fputts(_T("Input String 2 : "), stdout);
_tscanf(_T("%s"), str4);
_tcscat(str3, str4);
_tprintf(_T("String1 + String 2 : %s \n"), str3);
return 0;
}
|
cs |
정리
1. SBCS, MBCS, WBCS의 이해
2. 유니코드 기반 문자열 처리 함수
3. UNICODE와 _UNICODE
4. 유니코드 방식과 MBCS 방식을 모두 지원하기 위한 main 함수의 구성
'Windows > 윈도우즈 시스템 프로그래밍' 카테고리의 다른 글
| 7. 프로세스간 통신(IPC) 1 (0) | 2021.05.14 |
|---|---|
| 6. 커널 오브젝트와 오브젝트 핸들 (0) | 2020.06.15 |
| 5. 프로세스의 생성과 소멸 (0) | 2020.06.15 |
| 4. 컴퓨터 구조에 대한 두 번째 이야기 (0) | 2020.05.29 |
| 1. 컴퓨터 구조에 대한 첫 번째 이야기 (0) | 2020.05.29 |



